
[ad_1]
Results
Baseline characteristics
Of the 51 medical societies contacted, 34 (66.7%) agreed to distribute the survey. The survey was viewed 2360 times and data were collected from 817 participants between 18 April and 1 October 2024. Of these, 685 completed the survey (response rate 29.0%) and were included in the final analysis. Mean age (±SD) was 46.06 years (± 11.99), 398 (58.1%) of the participants were male and 511 (74.6%) were German speaking (table 1).
Primary outcome: frequency of general use of large language models
Primary outcome: frequency of general LLM use and multivariable associations with frequent use
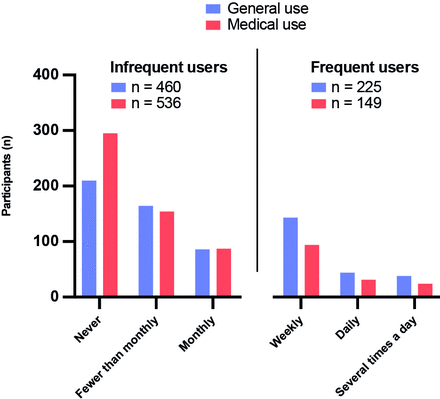
Of the 685 participants, 475 (69.3%) had used an LLM for general purposes at least once and 225 (32.8%) were frequent users (at least weekly use) (figure 1).
Comparison of frequency of general and medical use with dichotomisation into frequent (at least weekly) and infrequent (less than weekly) users.
Demographic factors associated with lower odds of frequent use were older age (47.13±11.90 years vs 43.86±11.91 years, adjusted OR 0.97, 95% CI 0.96 to 0.99, p<0.001) and female sex (adjusted OR 0.50, 95% CI 0.35 to 0.71, p<0.001) (table 1). Professional factors associated with lower odds of frequent use were working in private practice (adjusted OR 0.63, 95% CI 0.41 to 0.96, p<0.04), a tertiary hospital (other than university hospitals) (adjusted OR 0.58, 95% CI 0.38 to 0.9, p<0.02) and a primary hospital (hospital category as reported by participants, a link to the official categorisation by the Federal Office of Public Health was provided for guidance) (adjusted OR 0.5, 95% CI 0.28 to 0.9, p=0.02).
Professional factors associated with higher odds of frequent use were working in workplaces other than hospitals or private practices (adjusted OR 2.78, 95% CI 1.39 to 5.58, p=0.01), position as a consultant or head clinician (adjusted OR 2.53, 95% CI 1.16 to 5.51, p=0.02), research activity (adjusted OR 2.92, 95% CI 2.05 to 4.17, p<0.001) and availability of LLM guidelines in the workplace (adjusted OR 5.72, 95% CI 2.82 to 11.6, p<0.001).
A positive attitude towards LLM use, perceived usefulness of LLMs and perceived importance of AI knowledge were associated with more frequent use.
Frequency and purpose of medical use of LLMs
Among the 685 participants, 390 (56.9%) reported using an LLM for medical purposes at least once and 149 (21.8%) were frequent medical users (figure 1). Using LLMs as a knowledge resource was the most frequent purpose (182 participants, 26.6%), followed by scientific work (148 participants, 21.6%), teaching (143 participants, 20.9%), administration (142 participants, 20.7%), clinical reasoning and decision-making (102 participants, 14.9%) and communication with patients (98 participants, 14.3%) (figure 2A).
(A) Percentage of participants who have already used large language models (LLMs) for prespecified medical purposes. As this survey item allowed multiple selections, the total is >100%. (B) Comparison of models used for general and medical use. *Includes Llama (Meta), Claude (Anthropic), Le Chat (Mistral AI), Perplexity (Perplexity AI) and various others. †Participants were asked about their use of medical LLMs (ie, OpenEvidence, Med-PaLM, Meditron) in a separate item.
Use of LLMs as a knowledge resource was most prevalent among participants working in emergency and intensive care (37 participants, 32.7%). A higher proportion of participants from internal medicine-related specialties reported using LLMs for clinical reasoning and decision-making (52 participants, 20.3%) compared with those from other specialties (online supplemental file 5).
Models used for general and medical purposes
In total, 453 of 685 participants (66.1%) had used ChatGPT (OpenAI), 89 (13%) Bing Chat or Copilot (Microsoft, Redmond, Washington, USA), 49 (7%) Gemini or Bard (Google, Mountain View, California, USA) and 73 (10.7%) any other LLM (including Llama (Meta, Menlo Park, California, USA), Claude (Anthropic, San Francisco, California, USA), Le Chat (Mistral AI, Paris, France) and Perplexity (Perplexity AI, San Francisco, California, USA) (figure 2b). For medical purposes, 362 (52.8%) used ChatGPT (OpenAI), while no other LLM had been used by more than 40 participants. Notably, only 25 (3.6%) indicated having used any medical LLM (eg, OpenEvidence (Xyla, Cambridge, Massachusetts, USA), Med-PaLM (Google, Mountain View, California, USA), Meditron (École Polytechnique Fédérale de Lausanne, Lausanne, Switzerland).
Knowledge of LLMs and multivariable associations with higher knowledge
The median knowledge test score was 6 (IQR 4–8) points. Demographic and professional factors associated with lower odds of higher knowledge were older age (48.06±11.95 vs 43.68±11.62 years, adjusted OR 0.96, 95% CI 0.94 to 0.97, p<0.001), female sex (adjusted OR 0.32, 95% CI 0.23 to 0.46, p<0.001) and working in a tertiary hospital (other than university) (adjusted OR 0.64, 95% CI 0.41 to 0.98, p<0.05) (table 2).
Secondary outcome: knowledge about large language models
By contrast, research activity (adjusted OR 2.3, 95% CI 1.62 to 3.27, p<0.001) was the only professional factor associated with higher knowledge.
A positive attitude towards LLM use and perceived importance of AI knowledge were associated with higher knowledge.
Attitude towards the use of LLMs and multivariable associations with a positive attitude
Median VAS Score for the attitude towards the use of LLMs was 63 (IQR 45–76) points. Demographic and professional factors associated with lower odds of a positive attitude were older age, female sex and working in emergency and intensive care (online supplemental file 4).
The availability of LLM guidelines in the workplace was the only factor associated with a positive attitude.
An evaluation of participants’ perceptions of LLMs in clinical practice revealed an anticipated positive dynamic of their usefulness, a relatively high perceived importance of AI knowledge and, conversely, a low perceived preparedness for AI use (online supplemental file 6).
Qualitative analysis of LLMs’ opportunities and risks in clinical practice
The qualitative analysis showed that 446 of 685 participants (65%) identified at least one opportunity and 468 (68.3%) at least one risk associated with the use of LLMs in clinical practice. Three main themes emerged for both opportunities and risks, as summarised in figure 3.
Opportunities and risks of large language models as perceived by clinicians. Main themes were derived from free-text responses by iterative inductive thematic analysis.
The most frequently mentioned theme was organisation (63% of responses). Respondents emphasised the potential of LLMs to streamline documentation, simplify appointment scheduling and assist with administrative and routine tasks. Data assessment emerged as the second theme (49%), with responses focusing on the possible use of LLMs for analysis and interpretation, supporting clinical reasoning and decision-making, and bolstering research. The third key theme was information (30%), where participants underscored the role of LLMs in expediting knowledge availability and transfer, improving medical education, advancing patient education and facilitating patient–clinician interactions. Also, expected overarching benefits of LLM use were highlighted, including increased efficiency, improved quality, reduced errors and enhanced safety.
Concerns about user-related factors were the most frequently mentioned risks (54%). Respondents expressed worries about a potential decline in clinical knowledge, skills, linguistic competency and ingenuity, which could lead to clinician dependence on LLMs. Additionally, they raised concerns about the negative impact of LLMs on the patient–clinician relationship. Concerns about the models themselves ranked second (51%). Participants worried about the quality of model output, citing false information, hallucinations and bias that could result in incorrect diagnoses and treatment recommendations. Additionally, they voiced concerns about a lack of reproducibility and explainability of model output. The third theme focused on security, legal and ethical issues (35%), including data privacy risks, misuse and manipulation. Some respondents also considered the current legal and ethical frameworks for the use of AI in clinical practice to be inadequate. Finally, overarching perceived risks included insufficient control and unclear accountability.
[ad_2]
Source link



