
[ad_1]
Methods: participants, interventions and outcomes
Design
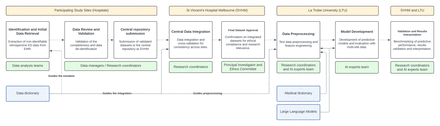
The proposed study design is to use routinely collected ED data (see table 1) in addition to recent presentation to hospital in the last 7 days, recent discharge from hospital in the last 28 days at each participating site to train and test the patient triage disposition prediction and type of admission model. The parameters of the model will be systematically optimised to maximise the performance of the model. The trained model will be validated by running the algorithm on the validation dataset of multiple sites. This study will involve the use of AI and machine learning (ML) algorithms. A working knowledge of data preprocessing techniques (eg, handling missing values, feature selection), large language models (LLMs), classification model development and performance evaluation metrics is required. The study team is experienced in applied AI and ML, clinical informatics and statistical analysis, which will enable appropriate model development and interpretation of results. Figure 1 shows the data preprocessing and analysis workflow.
Data processing and analysis workflow. AI, artificial intelligence; ED, emergency department; EMR, electronic medical record.
Study setting and participants
This multisite study will be conducted at nine Australian public hospitals with their own dedicated ED. The sites include St Vincent’s Hospital Melbourne (SVHM), Royal Melbourne Hospital (RMH), Monash Health (MH), Alfred Health (AH), Eastern Health (EH), Barwon Health (BH), Royal Hobart Hospital (RHH), Fiona Stanley Hospital (FSH) and Grampians Health (GH). Depending on the site, each attends to approximately 30 000–100 000 patients annually. Sites will include a mix of adult and paediatric EDs (MH, AH, BH, GH, RHH and EH) and adult EDs (SVHM, FSH and RMH). All sites receive patient populations from diverse demographic communities. Most sites are in metropolitan Melbourne, Victoria (SVHM, RMH, MH, AH and EH). GH and BH are in regional Victoria. FSH hospital is in metropolitan Perth, Western Australia, and RHH is in metropolitan Hobart, Tasmania. The sites have been selected to provide a representation of the Australian population within the feasibility of the study scope and budget. Our objective is to develop a dataset that includes a diverse mix of demographic characteristics for adult and paediatric patient populations across metropolitan and regional EDs. Furthermore, we aim to include a range of sites that have different ED triage processes and protocols.
There is no active recruitment required for this study. The study will require access to non-identifiable retrospective data at each of the study sites.
Outcomes
The primary outcome of this study is to use modern NLP techniques and ANNs to develop a predictive model that accurately predicts patient disposition (admission, discharge or other forms of care) and type of admission (medical, surgical, etc) based on emergency triage notes and routinely collected ED data (table 1). The patient disposition predictions will be assessed using standard classification metrics (accuracy, precision, recall and the F1 score). These metrics provide a comprehensive evaluation of model performance. The prediction will be defined as ‘accurate’ when the model demonstrates a value of more than 80% across these metrics, particularly precision and recall, which are critical for minimising false positives and false negatives in clinical decision-making contexts. The F1 score, as a harmonic mean of precision and recall, will be used as a key indicator of balanced performance. The key determinants of predictive precision will include:
-
The quality, completeness and relevance of input features (eg, triage notes, triage category, mode of arrival and demographic information of patients).
-
The choice and tuning of the AI and ML algorithms.
-
The handling of missing data and class imbalance.
-
Validation strategy.
-
Interpretability of model outcomes.
Secondary outcomes will be to investigate and determine the feasibility of using above-specified triage notes and routinely collected ED data to determine what triage note information contributes to the discriminative power in the model to predict disposition; predict short-stay admission and potential failed short-stay admissions; and benchmark predictive model performance across different ED data from different hospital study sites.
Sample size
Training and validating optimal ML algorithms require significant data. At each site, 10 years of non-identifiable patient data will be requested, with a minimum of 5 years of data needed. It is estimated that 10 years of data from participating sites will be up to approximately 800 000 to 1 million patient records. The proposed data sample size will include 7–9 million patient data records for training and testing the patient triage disposition prediction model.
Data collection methods
Data required for this study are routinely collected within Australian EDs. Data will be extracted at each site from their respective electronic medical record with support from their data analysis teams, for example, the Business Intelligence Unit at SVHM. A data dictionary (table 1) will be provided to each site to guide extraction. Data will be exported into Microsoft Excel.
Statistical methods
Several statistical methods will be used to characterise the data and interpret predictive outcomes, including the distribution of patient demographics, vital signs and other variables. Correlation analysis will be applied to compare cluster profiles and identify significant differences between patients with different dispositions.
Data preprocessing
Standard procedures of text normalisation will be applied in order to clean and standardise the textual triage data into an amenable form for NLP tasks. Tailored preprocessing pipelines will be employed due to the unique linguistic and content variations present in these triage narratives to extract vital signs and symptom concepts. LLMs and medical dictionaries will be employed to contextually reconstruct triage narratives by expanding medical abbreviations, simplifying texts and disambiguating them to improve linguistic quality, which seeks to aid human comprehension and enhance machine performance on NLP tasks. Furthermore, text features will be extracted using advanced preprocessing techniques to filter out non-medical terminologies and to focus on clinically relevant information. Moreover, structured data including extracted features will be preprocessed using standard preprocessing techniques such as categorical encoding, missing value treatment, binning, scaling and transformation.
Data analysis
The study will use NLP techniques, such as topic modelling and text feature extraction, will be employed to extract critical measurements such as vital signs from triage notes and routinely collected ED data. Cluster analysis will be performed on the extracted topics and text features to identify distinct patterns. Furthermore, a custom Bidirectional Encoder Representations from Transformers(BERT) model will be trained with the masked language modelling (MLM) technique to achieve optimum predictive capability.
The MLM technique allows BERT to be pretrained on large corpora of text efficiently by randomly masking a percentage of words in the input text and training the model to predict those masked words. For instance, in training, about 15% of the input tokens are masked and asking the model to predict them using the surrounding context. This way, BERT can develop a deep understanding of how words interact in a sentence, enhancing its bidirectional context comprehension. Once pretraining is complete, the model will be fine-tuned for the task of predicting disposition/type of patient admission using triage data. Thus, the MLM approach will ensure that BERT has a solid foundation of language understanding before it is adapted to prediction tasks.
To contextualise clinical information and patient demographics with the triage information, structured and unstructured data insights will be fused using ANN architecture (figure 2).
Predictive model architecture. LLM, large language model.
Validation and outcome interpretation
The predictive model will undergo rigorous testing, internal and external validation to ensure its effectiveness and generalisability in real-world scenarios. Internal validation methods will involve assessing the predictive accuracy of a model using the same dataset that was used to develop the model. Techniques such as cross-validation will be employed to assess realistic estimates of model performance measures. In contrast, external validation will involve testing the model on new data that will not be used in the model development process. This step will be crucial in assessing the transportability and reproducibility of the model. Various measurements such as accuracy, specificity, precision, recall, F1 score, area under the curve and confusion matrix will be used. Additionally, these outcomes will be benchmarked against human experts.
Data monitoring
This project does not require a data monitoring committee (DMC). Because we are using non-identifiable, retrospective and routinely collected ED data, there is negligible risk to the identification of patients. Additionally, no data will be shared or published as part of this study. Because this is a small-scale, investigator-initiated study, there is limited scope and scale for a DMC to be established. Additionally, as this is an early-stage feasibility study and the tool is not being implemented at this stage, ongoing monitoring is not required.
Future research
Future research will focus on the implementation and evaluation of the AI model at different sites to understand how it impacts real-world ED workflow, usability and utility and will include monitoring for any unintended consequences.
Consent or assent
There are no participants required for this study. This study only requires access to non-identifiable, routinely collected ED data. Resultantly, participant informed consent and participant safety considerations are not applicable to this study. The research team received a waiver of consent.
Confidentiality
All data will be collected in accordance with the Australian Code for the Responsible Conduct of Research and the requirements outlined in the National Statement on Ethical Conduct in Human Research.
All patient data will be made non-identifiable prior to training the model, as outlined in the National Statement on Ethical Conduct in Human Research. This process will include the removal of patient names, (Unique Record UR, patient number and any other identifying information.
We acknowledge the patient security and privacy constraints, including hallucinations, bias and possible data leakages associated with LLMs.13 Only deidentified data will be used with LLM tasks.
All data will be stored securely in password-protected files, and access will be limited to the research team.
[ad_2]
Source link



