
[ad_1]
Methods
Subject-matter experts
The clinical relevance and appropriateness of the evaluation framework were ensured through consultation with two subject-matter experts. HK, an internal medicine specialist with extensive PE experience, including service as the editor-in-chief of the King Abdullah Bin Abdulaziz Arabic Health Encyclopaedia, provided guidance on general medicine topics and PE best practices. Additionally, MA, an oncology specialist at Al Amal Hospital, Qatar, offered specialised oncology expertise. Both experts contributed to defining relevant clinical topics, validating the evaluation questions and assessing the generated LLM responses.
RAG data corpus
Online supplemental table S1 lists the reliable public websites we used to collect our 52 k article ARAG data from. We selected those sources based on an expert consultation in Arabic-based PEMs. We collected the data using the Firecrawl API from Python. The data were collected between August and October of 2024.
Embedding models selection and chunking strategy
The model selection process identified reputable models supporting Arabic, primarily via the Massive Text Embedding Benchmark,21 excluding fine-tunes from smaller teams for reliability. The candidate models identified included ‘bge-m3’, ‘granite-embedding-278m-multilingual’, ‘static-similarity-mrl-multilingual-v1’ and ‘jina-embedding-v3’ (further details in online supplemental table S2).
A dedicated testing methodology using samples from the project’s Arabic medical corpus (three distinct article/question pairs: prostate cancer, lentil soup, breast cancer) determined the selection. For each candidate model, embeddings were generated for these six texts, and cosine similarities were computed for each article-question pair, forming a 3×3 matrix. This approach aimed to quantify how well models handled unrelated (cancer-lentil) and related (breast-prostate cancers) topics. The goal was a model assigning high similarity to correctly matched pairs and low similarity to unrelated pairs. By comparing these matrices, the model showing the greatest contrast between correct and incorrect matches, ‘jina-embedding-v3’22 (hereafter ‘jina-v3’), was selected. Online supplemental table S3 presents these experimental results.
Sentence-wise chunking was selected as it avoids context loss from splitting midsentence (unlike naive token chunking) and is less computationally demanding than semantic chunking.23 Following recommendations for RAG deployments suggesting 512–1024 tokens per chunk for scientific articles,23 we targeted approximately 512 tokens. This smaller size increases information granularity within the vector database, creating more, smaller chunks. This approach allows retrieval to access diverse relevant passages, mitigates bias from over-reliance on a single large chunk and answers complex queries requiring information synthesised from multiple segments. To achieve the target chunk size based on our data’s characteristics (online supplemental table S4), we calculated the number of sentences corresponding to 512 tokens. With an average of 44.53 tokens per sentence, this resulted in 11 sentences per chunk: 512(token/chunk)/44.53(token/sentence) ≈ 11(sentence/chunk).
LLMs and ARAG deployment
Given the sensitive nature of patient data and our future plans for patient data integration, our approach focused on open-source LLMs deployable locally. This ensures transparency for data privacy and minimises risks associated with external patient data transmission. An exception was made for Fanar,24 the Qatari sovereign LLM; although closed-source, its local development allows for on-premises deployment.
Practical challenges hinder deploying LLMs >32B parameters in local hospitals (eg, computational resources, costs, AI Graphic Processing Units (GPUs) import complexities), rendering larger models unsuitable for this project’s required scale.
Furthermore, we focused on models trained on Arabic data to process Arabic queries and the Arabic RAG corpus effectively.
Based on these constraints, four selection criteria were defined: (1) source: open-source/-weights (exception: Fanar), (2) size: ≤32B parameters, (3) language: Arabic support and (4) origin: reputable source. Applying these criteria via Hugging Face, web search and the Open Arabic LLM leaderboard25 resulted in the selection of the following 12 LLMs: Qwen-2.5 (7b, 14b, 32b), Phi-4 and Phi-4-mini models, alongside Mistral-Small-2409, Gemma-2-27b, Fanar-7B, Falcon3-10B, jais-family-13b, jais-adaptive-13b and AceGPT-v2-32B (details in online supplemental table S5).
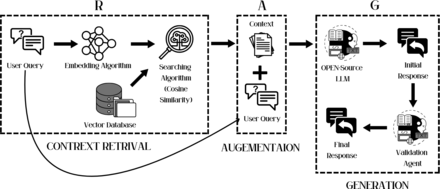
To address PEM sensitivity and enhance safety, a VA was integrated into the RAG pipeline, after LLM response generation. The VA’s core task is to validate safety by assessing text for harmful or unsuitable information, performing minor revisions for appropriateness (eg, tone) and blocking harmful responses. This agent is implemented via a second inference call to the same base LLM, guided by a distinct, specialised prompt for validation and safety filtering (details in online supplemental table S6). Figure 1 depicts the proposed ARAG framework.
Diagram depicting our proposed ARAG framework for PEM generation. ARAG, agentic retrieval-augmented generation; LLM, large language model; PEM, patient education material.
Datasets for evaluations
For the PEM generation evaluation exercise, our question acquisition methodology was adapted from.26 Candidate PEM topics within general medicine and oncology were initially identified through multiple rounds of phone consultation with subject-matter experts for relevance to patient needs. An initial pool of 50 common patient questions (25 general medicine, 25 oncology) was compiled from medical sources (eg, American Academy of Ophthalmology, National Cancer Institute, National Health Service). This pool was then reviewed by the experts, who selected the final 20 questions (10 general medicine, 10 oncology) based on representativeness of typical patient inquiries. For the full list of questions and ground truth answers, consult online supplemental datasets, sheet ‘PEM Questions’.
As for assessing the VA performance, a dataset of 50 PEM examples (details in online supplemental datasets, Sheet ‘VA PEMs’) was created. The dataset was physician validated through an online form. This dataset included three categories featuring harmful medical advice, ranging in severity from potentially life-threatening (category 1) to unscientific (category 3), subtly integrated within otherwise safe-appearing PEMs to test the blocking capabilities of LLMs. Two non-harmful categories with different tones served as controls. Each category contributed 10 PEMs totalling 50 PEMs.
PEM generation experimental setups and inference
To evaluate the selected LLMs for Arabic PEM generation and assess our ARAG’s contribution, we designed four experimental setups: (1) base LLM performance; (2) base LLM with prompt engineering; (3) ARAG without prompt engineering and (4) ARAG with prompt engineering. Each of the 12 LLMs was evaluated under all configurations, totalling 48 experimental runs (12 LLMs×4 configurations). Figure 2 details the experimental setups and evaluation framework.
Overview of the evaluation framework, detailing the candidate LLMs, the experimental setups and the two-round evaluation. ARAG, agentic retrieval-augmented generation; LLM, large language model.
The adopted prompt engineering techniques for setups 2 and 4 can be found in online supplemental table S6. For configurations using ARAG (setups 3 and 4), the augmented context was limited to the top 3 chunks with the highest cosine similarity scores relative to the user’s query (≈1536 tokens). This standard context limit ensured compatibility across all evaluated LLMs by accommodating the smallest context window. To illustrate, the ‘Jais-family’ model has a 2K token capacity (online supplemental table S5), making it unfeasible to supply more than 3 chunks (≈512 tokens each). The 1532 token limit was tested for sufficiency prior to results generation and was found to be adequate in 10 distinct scenarios.
For all 48 experiments, default inference settings were applied. Each evaluation question was formulated as a zero-shot input, augmented with contextual data and/or specific prompt engineering as dictated by the experimental setup. Three distinct inference methods were employed based on model characteristics (detailed in online supplemental table S7): Local deployment: open-source models with ≤14B parameters were run locally using the Ollama framework on an NVIDIA RTX 3090 GPU. Inference application programming interface (APIs): models >14B parameters or closed-source models like Fanar-7B were accessed via their respective APIs. Dedicated cloud deployment: AceGPTv2-32B, which was not available via standard APIs, required deployment on a dedicated cloud virtual machine equipped with an NVIDIA A100 GPU.
PEM generation evaluation methodology
A two-stage process evaluated the 48 PEM generation experiments (figure 2): an initial automated assessment using an LLM, followed by manual evaluation by domain experts.
The evaluation metrics were carefully selected for this task. Accuracy, readability and comprehensiveness were chosen based on their identification as key criteria in a prior scoping review.9 Additionally, safety and appropriateness were included following recommendations from a PEM specialist. These metrics are defined as follows: accuracy (factual correctness); readability (ease of language); comprehensiveness (how fully the question was addressed); appropriateness (suitability of tone, style and cultural context) and safety (absence of harmful or misleading advice).
Both evaluation stages assessed responses using identical metrics against ground truth answers on a 1–5 Likert scale. The initial automated stage employed ChatGPT o3-mini27 as the evaluator, guided by an engineered prompt (details in online supplemental table S6). During this stage, a language validation rule was applied, assigning a zero score across all metrics for responses containing non-Arabic sentences; this aimed to ensure suitability for the target audience and avoid compromising patient engagement or trust due to language switching. Based on the resulting scores, the top 5 experiments were identified. In the second stage, domain experts independently re-evaluated these top 5 configurations using the same criteria via online forms which displayed: the question, the ground truth answer and the LLM response to the domain experts. Experts performed the evaluations blindly, unaware of models’ identities.
VA evaluation methodology
To evaluate the candidate LLMs’ ability to function as VAs blocking harmful PEMs, an independent test benchmarked their instruction-following and harmful content detection. LLMs were instructed via few-shot examples to respond with, ‘I am sorry I cannot help with this’ to harmful PEMs, adherence was measured by the cosine similarity (jina-v3 embeddings) between the LLM’s response and this target phrase. Based on a determined similarity threshold, responses were classified as refusals (‘Yes’) or not (‘No’). Comparing these classifications against ground truth yielded standard metrics: true positive, false positive, false negative and true negative. These metrics were used to calculate the overall accuracy for each LLM as a VA.
[ad_2]
Source link



