
[ad_1]
Discussion
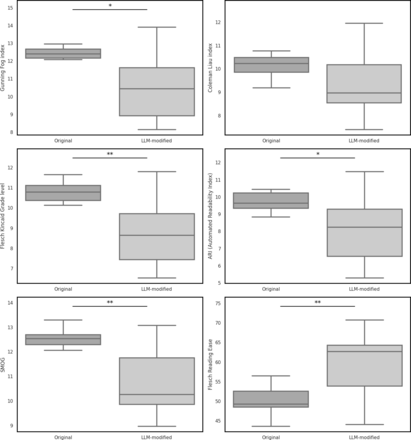
Our study aimed to leverage a widely available LLM and assess its ability to improve the readability and maintain the factual accuracy of publicly available PILs published on the CIRSE website. The recommended reading age PIL text should be written at is grade 6 (11–12 years) as recommended by the American Medical Association.9 Interestingly, neither the original PILs nor the LLM-modified PILs were able to achieve this. Previous literature published assessing the readability of specifically CIRSE PILs is congruent with the analysis carried out in this study. Hansberry et al17 analysed the readability of CIRSE web resources and found they were collectively written at a grade level of 12.3 (although this was more recently reassessed by Rahmani and O’Sullivan,18 who found this to be slightly improved).
In general, LLMs were able to improve PIL readability demonstrated by the reduction of mean reading grade from 11 (16–17 years) to 9.5 (14–15 years). This finding is similar to those presented by Ali et al,19 who examined the role of GPT-4 in simplifying surgical consent forms and reported an improvement of readability with the preservation of factual content. However, compared with this study, we found that there was greater variation in the LLM performance in its ability to improve document readability. For example, some leaflets (eg, image guided percutaneous biopsy) became more linguistically complex after LLM modification. There was also heterogeneity in the degree of improvement in some leaflets’ readability with some leaflets demonstrating minor improvements (percutaneous fluid and abscess drainage; Δ grade −0.4) and some demonstrating drastic improvements (peripherally inserted central catheters; Δ grade −3.8).
Although mean reading grade tended to worsen with increased PIL word count, when this was further interrogated with subgroup analysis, the relationship was reversed in the original PIL cohort and lost in the LLM-modified cohort (figure 3). These findings suggest that the relationship between readability and word count is more complex, and that improved readability is not simply a product of reducing word count.
Correlation between mean reading age and number of words. Green: original PILs, red: LLM-modified PILs and blue: original and LLM-modified PILs. LLM, large language model; PILs, patient information leaflets.
An important component of our study was evaluating whether the simplification of documentation significantly compromised the factual accuracy of the PILs. Two LLM-modified PILs were reviewed and found to have no concerns, while ten were identified as having minor concerns. No errors that could have resulted in serious patient harm were detected in the LLM-modified PILs. In general, the LLM-modified PILs exhibited a degree of factual inaccuracy, although these inaccuracies tended to be low in frequency and relatively minor. It is likely, therefore, that the process of using LLMs to simplify PILs will still require a human-in-the-loop framework to ensure that quality is not compromised. Our results are similar to those reported by Abou-Abdallah et al,13 who used an earlier model, ChatGPT 3.5, to simplify explanations of common surgical procedures and also found that this simplification was achieved at the expense of response quality. More recently, in a study comparing the performance of LLMs with and without expert input to improve the readability of vaccination consent forms, Cosma et al concluded that the best results are seen in a hybrid approach, with LLM output being supervised by human experts.20 However, other research teams have concluded that LLM-modified patient information is of sufficient quality to be considered accurate.19 21 The difference in conclusions among these similar studies may be attributed to variations in the subjective scoring of LLM-modified PILs and the complexity of the content being discussed.
Our study had several limitations. First, PILs often contain pictorial information which is an important adjuvant to text-based information and aid patient understanding. Pictorial information is particularly valuable in improving patient understanding in patients with low literacy.22 However, assessment of pictorial information was outwith the scope of this study. Despite this, PILs still rely heavily on the use of text to convey information and therefore improving the text-based component of these articles is still of value. On a similar note, the layout and presentation of the text play an important role in readability of an article and are an explicit area of focus in designing effective PILs.23 We chose to reformat articles for the human evaluators with the goal of making comparison, and therefore error detection easier. At the time of writing, the CIRSE website offers the same PILs we have studied in 19 other languages which may be written at different readability levels and are not assessed in this study. However, for an initial feasibility study, we have first assessed on English text, which is common practice in the benchmarking of LLM performance.24 Furthermore, we did not include direct patient usability testing to confirm that the improvement seen with LLM-modified PILs was replicated within our target population. Future research should incorporate patient-centred evaluation methods, such as think-aloud protocols during PIL review25 and comprehension questionnaires. Such testing could be conducted with diverse patient populations to ensure PILs meet the needs of varied literacy levels, cultural backgrounds and health conditions. Finally, this study was constrained to evaluation of a single LLM (GPT-4), selected based on its widespread adoption at the time of writing, without comparative assessment of alternative models or exploration of different model variants. We do not endorse its specific use and anticipate that other models may exhibit varying performance characteristics, thereby limiting the generalisability of our findings across the broader landscape of available language models.
[ad_2]
Source link



