
[ad_1]
Abstract
Objective To evaluate the transferability of BERT (Bidirectional Encoder Representations from Transformers) to patient safety, we use it to classify incident reports characterised by limited data and encompassing multiple imbalanced classes.
Methods BERT was applied to classify 10 incident types and 4 severity levels by (1) fine-tuning and (2) extracting word embeddings for feature representation. Training datasets were collected from a state-wide incident reporting system in Australia (n_type/severity=2860/1160). Transferability was evaluated using three datasets: a balanced dataset (type/severity: n_benchmark=286/116); a real-world imbalanced dataset (n_original=444/4837, rare types/severity<=1%); and an independent hospital-level reporting system (n_independent=6000/5950, imbalanced). Model performance was evaluated by F-score, precision and recall, then compared with convolutional neural networks (CNNs) using BERT embeddings and local embeddings from incident reports.
Results Fine-tuned BERT outperformed small CNNs trained with BERT embedding and static word embeddings developed from scratch. The default parameters of BERT were found to be the most optimal configuration. For incident type, fine-tuned BERT achieved high F-scores above 89% across all test datasets (CNNs=81%). It effectively generalised to real-world settings, including rare incident types (eg, clinical handover with 11.1% and 30.3% improvement). For ambiguous medium and low severity levels, the F-score improvements ranged from 3.6% to 19.7% across all test datasets.
Discussion Fine-tuned BERT led to improved performance, particularly in identifying rare classes and generalising effectively to unseen data, compared with small CNNs.
Conclusion Fine-tuned BERT may be useful for classification tasks in patient safety where data privacy, scarcity and imbalance are common challenges.
Introduction
Patient safety is a major concern, with adverse events and harm occurring in approximately 10% of hospital admissions,1 about one-third of which are preventable.2–4 Reports about patient safety incidents are a crucial resource for understanding underlying causes and mechanisms.5 Incident analyses identify recurring patterns and trends, thereby facilitating learning and preventive strategies at multiple levels, from individual hospital to health system and national levels.6 Identification of clusters across settings can help learning from local experiences to change practices at the higher levels. However, current methodologies hinder population level learning as they rely on time-consuming reviews by humans. With the wide implementation of incident monitoring systems, the growing volume of reports is a challenge for timely incident response and active learning.5 7
Categorising incidents by type and severity level is crucial for learning and prioritising incidents requiring immediate response.6 One solution is to ask reporters to categorise incidents using standardised structures, such as the AHRQ Common Formats which facilitate collection of essential information such as incident type, date/time, description and follow-up actions.8 However, accuracy cannot be guaranteed as reporters are healthcare professionals who may lack specific expertise.9 Furthermore, categorisation by reporters may be absent or incomplete, hampering response.9
Background and significance
To improve efficiency, machine learning methods have been applied to automate incident identification.10–17 Traditionally, various domain-specific text classifiers using unsupervised and supervised learning have been shown to be effective in categorising reports into predefined types.10 11 15 18 However, unsupervised methods (eg, topic modelling) encounter challenges in establishing clear mappings between topics and incident types, as topics can span multiple types.13 For example, medications might involve patient identification and clinical handover errors.11
Supervised learning provides more direct incident classification but requires expert annotation. We have developed Support Vector Machine (SVM) ensembles to identify 10 primary incident types.11 19 While this approach was effective for identifying common incidents, such as falls and medications, it does not generalise to independent reporting systems.10 11 Encouragingly, convolutional neural networks (CNNs) achieved better generalisability than SVMs.20 However, their performance was constrained by limited data availability, especially for rare types (eg, clinical handover <1%).
Large language models (LLMs) have demonstrated remarkable capabilities in text classification, question-answering and beyond.21–23 Their inherent adaptability from pretrained knowledge to specific domains shows promise for incident identification.16 17 24–31 In clinical and biomedical research,22 BERT (Bidirectional Encoder Representations from Transformers) stands out as a benchmark LLM, playing a pivotal role in extracting valuable insights from unstructured text, such as electronic health records (EHR),25 26 32 medical literature28 33 and patient summaries.29 32 While BERT models have been adapted for tasks such as disease prediction,30 risk assessment,34 EHR anomaly detection29 35 and treatment optimisation,32 these clinical models are often finetuned to particular diseases or treatments. Their domain-specific nature restricts knowledge sharing and limits their transferability.19 36 37 In particular, incident reports which differ from clinical notes and the medical literature in their narrative style, focusing more on storytelling of incidents than clinical jargon.38
Instead of using clinical or biomedical models, a general BERT that prioritises narrative structure over the intricacies of clinical terms may be more suitable for identifying incidents.21 39 BERT remains a benchmark due to its compact size, lower computational requirements and effectiveness in adapting to domain-specific tasks.28 29 34 However, the feasibility of applying LLMs to identify incidents has not been explored previously. We investigated two strategies: (1) fine-tuning a pre-trained BERT model with incident reports by leveraging expert report annotations to identify multiple types and severity levels; (2) using BERT word embedding to extract features, with development of a small CNN for incident classification. We compare these two approaches to our prior CNN models with static word embedding.10 20 Lastly, we conducted error analysis to investigate how BERT’s pre-trained knowledge identifies intricate patterns and connections in incidents, providing insights for other patient safety tasks.
Materials and methods
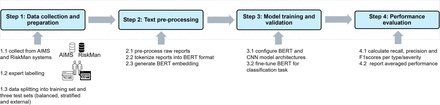
The study procedure is shown in figure 1.20
Study procedure. AIMS, Advanced Incident Management System; BERT, Bidirectional Encoder Representations from Transformers; CNN, convolutional neural networks.
Step 1: data collections and preparation
Incident reporting systems
The Advanced Incident Management System (AIMS) was used in four Australian states and territories (New South Wales, Western Australia, South Australia and Northern Territory).6 40 Incidents were categorised into 20 types by reporters, with common types like falls and medication comprising 54% of all reports, while rare types (eg, deteriorating patient) constituted only 5–6%.10 On average, 130 000 incidents were reported annually to AIMS in one state. To ensure a representative sample, 300 reports were randomly collected for each type, guided by reporter labels. In total, 6000 reports were collected from AIMS between January and December 2011.
The Riskman system is another tool used in the state of Victoria and several private hospitals across the country.10 11 A total of 6000 incident reports were randomly selected from a hospital-level system between January 2005 and July 2012. Any identifiable information, such as names or birth dates, was removed in compliance with jurisdictional privacy requirements.
Data labelling
The reports were reviewed and classified into 20 incident types by patient safety experts using the international classification for patient safety.41–43 We focused on 10 priority types for safety and quality improvement (table 1).2 6 10 To cover the entire dataset, an ‘Others’ category was created using random sampling approach to ensure representativeness of the 10 remaining types (see details in previous work10). Incident severity was determined by the internationally recognised Severity Assessment Codes (SAC) from the US Veterans Administration.44 Four risk ratings (extreme, high, medium, low) were assigned by trained patient safety managers based on severity and recurrence likelihood.
The composition of balanced used for fine-tuning BERT and extracting features using BERT word embedding while stratified datasets were used for testing
Data splitting
To fine-tune BERT, we created a balanced dataset using 260 reports from each incident type and 290 reports for each severity level (table 1).10 20 The balanced dataset was split into training (80%), validation (10%) and testing (10%) subsets using 10-fold subsampling cross validation. Training and validation subsets were used to optimise BERT parameters, while the testing subsets served as a benchmark to assess model generalisability.
To assess real-world performance, models were tested on imbalanced, that is, ‘stratified’ datasets from AIMS (original). These datasets were randomly selected from the remaining AIMS reports, maintaining real-world ratios by type and severity (table 1). To examine generalisability to different reporting systems, the models were tested using a stratified Riskman dataset (independent).
Step 2: text preprocessing
Incident reports consist of structured (eg, ID, date) and free-text fields describing safety events and their consequences. Only the descriptive narratives from text fields were combined and used as model input for experiments, in the following order: incident description/detail, patient outcome, actions taken, prevention steps, investigation findings and results. All codes, punctuation and non-alphanumerical characters were removed, and the text was converted to lowercase.
Leveraging the BERT tokeniser, we tokenised preprocessed text data into subword sequences, assigning each token a corresponding embedding vector.24 BERT also adds positional embeddings to understand the sequential order of words in sentences, for example, a classification token (CLS) was used for overall context at the beginning of sequence, and a separator token (SEP) for denoting sentences or segment boundaries.
Unlike traditional models that require fixed-length input, BERT handles text inputs of varying lengths through its attention mechanism, which dynamically assigns weights to different parts of a sequence.24 However, for efficient batch processing, consistent sequence lengths are required.45 Padding and truncation techniques are employed for length matching. When padding, a (PAD) token is appended at the end of shorter sequences and treated as a neutral element without significance during BERT training. Lengthy reports were truncated from the bottom, prioritising narratives in descriptions over incident management information. To optimise model performance, fine-tuning was conducted with a soft input sequence length ranging from 75 (median report length) to 512 (default BERT’s maximum token limit).
Feature representation
BERT’s word embedding captures the meaning of a word based on its surrounding context in sentences. We used this flexibility to generate word vectors as input features for the subsequent CNNs. The embedding dimensionality (vector size) is treated as a parameter in the word-embedding space, optimised within a range from 256 to 768 (default size in BERT base model).
Step 3: model training and validation
BERT configuration
We customised a pretrained BERT base model architecture to our specific classification tasks by adding a multiclass classification head and modifying its output layers to align with the number of incident types and severity levels as model’s output (n_type/severity=11/4).45 Given limited training data, we used a small batch size of 32 and fine-tuned for four epochs over the datasets for the two classification tasks. For each task, we grid searched over lower learning rates in (0.00005, 0.00004, 0.00003, 0.00002 and 0.00001) with Adam optimiser and a weight decay factor of 0.01. Model selection was based on loss function with a validation set and we chose the best performing checkpoint.
CNN configuration
CNN architectures were adopted from our previous study, including the input, a single convolution and rectifier, fully connected and classification layers.20 For incident type, 20 filters were applied to the convolution layer, scanning through a (2,2) region in the word-embedding space.20 The best-performing embedding dimensionality was 100 and report length was 75. For severity level, the most effective input layer setting was 120-dimension embedding space with 60-word long report. The convolution operation used 10 filters to scan over a region of (3,3) of input layer.20
Step 4: performance evaluation
Individual classification performance
F-score, precision and recall measures were used to assess classifier’s performance on individual incident types and severity levels.10 11 20 A confusion matrix was used to visualise results.
Overall classification performance
Two standard measures were examined: micro-averaging and macro-averaging, with the former considering cumulative number of true/false positives and negatives per class, while the latter calculating the average performance scores over all classes with equal weight (online supplemental appendix A).10 20 The best fine-tuned BERT was evaluated on benchmark, original and independent datasets. We also compared performance to CNNs with BERT embedding and to our previous CNNs with local/static word embedding.20
Conclusion
Our study underscores the effectiveness of fine-tuned BERT for classifying patient safety incidents by type and severity. Default BERT configurations to input layer proved efficient in both classification tasks, negating the need for extensive parameter tuning. Furthermore, BERT’s enhanced performance in identifying severity levels suggests its suitability for smaller classification tasks, especially when fine-tuned with limited data. Finally, BERT demonstrates improved generalisability on unseen data than small CNNs. However, error analysis emphasised the importance of distinct task definitions and avoiding broad labels.
[ad_2]
Source link



