
[ad_1]
Materials and methods
Our entire research was AI-based, using the capabilities and sage advice from ChatGPT (OpenAI, model 4o). The AI engine used Python programming language to construct scripts for all data collection and statistical analysis. These scripts were deployed through ChatGPT’s interface, using Google Colab or locally. The code will be uploaded to an open repository. The only part performed fully manually was the writing of this paper, which was then handed to ChatGPT merely for proofreading and light sparkle.
We included publications from the top 50 journals in medicine (according to the 2022 Web of Science, Journal Citation Report) in our initial analysis. ChatGPT constructed a script, using PubMed Pythonic application programming interface (API), retrieving all accessible abstracts and articles metadata from these journals, dating 10 years ago and up to June 2024.
Our search yielded 315 309 articles from all journals, including each article’s title, writers, abstract, and year and month of publication. For reasons known only to the AI deities, four journals yielded no results using our AI-based methods. After eliminating duplicate or erroneous entries, 212 620 individual articles remained. We did not attempt to retrieve the missing data manually to keep our AI-based approach intact.
Our initial method of determining if an article was AI-related was using AI-related keywords in each article’s content. Examining the results, however, showed this method to be either too constrictive or too permissive. Therefore, we turned to an AI-based approach, using ChatGPT to write a Python script processing each line in the table as an individual query through OpenAI API with the instruction “Please answer TRUE or FALSE only, is the following article definitely AI-related:”. To validate this method, we randomly selected a sample of 20 articles and debated with ChatGPT regarding the rationale and credibility of its decisions. Convinced of its validity, we used this method for the AI relation determination.
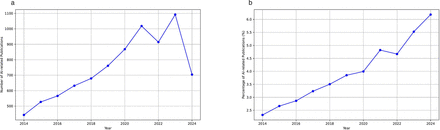
We analysed the results over time, plotting the total absolute and relative number of AI-related publications per year and per month. We used linear regression to fit several trendlines, incorporating polynomial features to capture non-linearity and plotted 95% CIs.
To address any variation between different fields in medicine, we plotted the relative number of AI-related articles over the years, stratified by the predominating categories in our data: cardiology, general medicine, oncology, neurology and other specialties. The AI engine added another category of ‘unknown’ for articles it could not classify. We also plotted a smoothed graph of this data, using a rolling average calculation with a delta of 3 years.
Finally, we created two models to predict the use of AI in future publications and to forecast the date when all articles in the field of medicine will be AI-related. The models we used were autoregressive integrated moving average (ARIMA) model and an error-trend-seasonality (ETS) exponential smoothing model.
This study was conducted and reported in accordance with the Strengthening the Reporting of Observational Studies in Epidemiology guidelines.
[ad_2]
Source link



