
[ad_1]
Abstract
Objectives The objective of this study is to evaluate whether large language models (LLMs) can achieve performance comparable to expert-developed deep neural networks in detecting flow starvation (FS) asynchronies during mechanical ventilation.
Methods Popular LLMs (GPT-4, Claude-3.5, Gemini-1.5, DeepSeek-R1) were tested on a dataset of 6500 airway pressure cycles from 28 patients, classifying breaths into three FS categories. They were also tasked with generating executable code for one-dimensional convolutional neural network (CNN-1D) and Long Short-Term Memory networks. Model performances were assessed using repeated holdout validation and compared with expert-developed models.
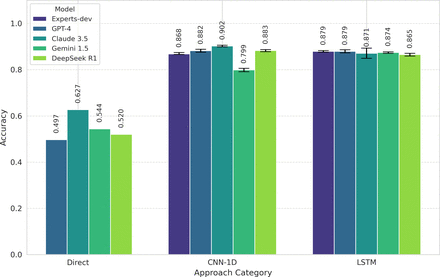
Results LLMs performed poorly in direct FS classification (accuracy: GPT-4: 0.497; Claude-3.5: 0.627; Gemini-1.5: 0.544, DeepSeek-R1: 0.520). However, Claude-3.5-generated CNN-1D code achieved the highest accuracy (0.902 (0.899–0.906)), outperforming expert-developed models.
Discussion LLMs demonstrated limited capability in direct classification but excelled in generating effective neural network models with minimal human intervention. This suggests LLMs’ potential in accelerating model development for clinical applications, particularly for detecting patient-ventilator asynchronies, though their clinical implementation requires further validation and consideration of ethical factors.
Introduction
Mechanical ventilation is a life support treatment for critically ill patients; however, patient-ventilator asynchronies can compromise outcomes.1 2 Real-time detection of asynchronies, particularly episodes of flow starvation (FS), remains a critical clinical challenge at the bedside. Deep neural networks have shown promising results in classifying certain asynchronies such as FS. Nonetheless, their design and development are time-consuming. In contrast, large language models (LLMs) could offer a potential solution to enhance efficiency and save time for clinical applications.3 This study aims to explore whether LLMs can achieve performance comparable to expert-developed deep neural networks in the detection of FS asynchronies,4 5 either through direct classification or by generating functional code for established network architectures.
Methods
We evaluated LLM performance in classifying FS asynchronies using a previously established dataset that includes individual breath cycles from real-time respiratory data of 28 critically ill patients undergoing mechanical ventilation.6 In a prior study, clinicians labelled 6500 airway pressure cycles from this dataset into three categories (‘No FS’; ‘Mild FS’; ‘Severe FS’) and subsequently developed and trained two neural network models: a one-dimensional convolutional neural network (CNN-1D) and a Long Short-Term Memory recurrent network (LSTM).6 In the present study, popular LLMs7 (OpenAI’s GPT-4, Anthropic’s Claude-3.5, Google’s Gemini-1.5, and DeepSeek’s R1) were first tested for their ability to directly classify the individual breaths into the three FS categories based on pressure waveform data. Subsequently, these LLMs were prompted to generate code implementing CNN-1D and LSTM networks suitable for this classification task. A mandatory requirement was that the LLM-generated code should be executed free of errors, with little to no human intervention. To assess model performances, repeated holdout validation was carried out using an 80/20 dataset split for train/test and 15 repetitions. Finally, the average performances of the LLMs-generated models were compared with that obtained from the experts-developed networks.
Results
LLMs direct classification of FS yielded poor accuracy results: 0.497 for GPT-4, 0.627 for Claude-3.5, 0.544 for Gemini-1.5 and 0.520 for DeepSeek-R1. However, when LLMs were prompted to generate code for CNN-1D and LSTM networks, the resulting models achieved remarkably capable performances. Notably, Claude-3.5’s CNN-1D network achieved the best overall performance, with an accuracy score of 0.902 (0.899 to 0.906), surpassing the experts-developed deep learning models. Figure 1 provides a visual comparison of the accuracies, while table 1 summarises the key performance metrics for all tested models.
Model accuracy comparison with confidence intervals. Direct, CNN-1D (one-dimensional convolutional neural network) and LSTM (Long Short-Term Memory network).
•
Average performance metrics for all evaluated models
Claude-3.5’s CNN-1D model displayed a balanced classification across FS categories, misclassifying fewer severe cases compared with other models. The experts-developed LSTM model, however, showed superior specificity in distinguishing extreme categories (‘No FS’ and ‘Severe FS’), indicating that it was less likely to misclassify extreme cases.
Discussion
The results indicate that, while current general-purpose LLMs struggle with direct time-series classification tasks like FS detection from pressure waveforms, they possess a remarkable capability to generate specialised code for deep learning models with minimal human input. The CNN-1D model generated by Claude-3.5 outperformed even the expert-developed models in overall accuracy, possibly due to its well-suited architecture (eg, the use of three convolutional blocks with batch normalisation and Rectified Linear Unit (ReLU) activations, identified through the LLM’s generative process) compared with potentially simpler architectures generated by other LLMs or different design choices made by human experts. The superior specificity of the expert-developed LSTM in distinguishing extreme FS states highlights that different architectures may offer specific advantages, potentially reducing risks associated with undetected severe FS or unnecessary interventions.
Our findings suggest that future research could focus on integrating LLM-assisted model generation into clinical decision-support systems. This paradigm shift could accelerate the development of tailored algorithms for real-time patient monitoring and scalable detection of ventilator asynchronies in diverse clinical settings, while reducing costs and expertise barriers.
The model development relies on certain assumptions, primarily that the dataset is representative, the input features contain sufficient information for classification and the expert labels are accurate. These assumptions influence the model’s performance and reliability and may limit the generalisability of our findings to broader patient populations or different ventilator settings, emphasising the need for validation on larger, multicentre datasets.
Potential barriers to implementation include integration with existing clinical information systems, ensuring real-time data processing capabilities with adequate computational resources, and addressing clinicians’ trust in AI-generated models. These challenges may be overcome through close collaboration with healthcare IT teams and the development of comprehensive user training programmes. Overcoming these barriers, continuous monitoring of airway pressure deformation with these models could alert clinicians about periods with excessively high inspiratory efforts or insufficient airflow, enabling them to personalise interventions aimed to minimise intervals of potentially injurious patient-ventilator interaction.
The use of AI in critical care raises important ethical concerns, particularly regarding model errors that could lead to harmful clinical decisions. Over-reliance on AI recommendations—known as automation bias—may cause clinicians to overlook the technology’s limitations. Furthermore, AI systems trained on biased or incomplete data risk perpetuating or exacerbating health disparities among vulnerable populations. Data privacy also remains a critical concern, given the large datasets required for AI model development and the sensitive nature of patient information. To address these challenges, ethical frameworks emphasising transparency, human oversight, robust data governance and the development of trust algorithms are essential. Fundamentally, AI should serve as a supportive tool rather than a replacement for expert judgement in critical care environments.
Future research should prioritise validating these models in larger, more diverse patient cohorts and exploring the integration of multimodal data—including additional physiological signals and electronic health record information. Additionally, leveraging advances in AI technologies such as domain-specific LLMs, supervised learning and federated learning to enhance model robustness, adaptability and generalizability across varied clinical environments.
[ad_2]
Source link



