
[ad_1]
Materials and methods
The present study pursued a multicentre approach using 3674 anonymised images of the departments of dermatology of the University Hospitals in Essen and Erlangen and the Wound Centre of the Christian Hospital in Melle, a municipal hospital, all of them located in Germany. Images of leg and foot ulcers, that is, with the subtypes VLU, ALU, MLU and DFU and images of PG originated from the University Hospital Essen and Erlangen. The hospital in Melle contributed images of DFU. The images were taken during routine wound care and entered into the digital medical and wound record systems. Inclusion criteria at all sites were International Statistical Classification of Diseases and Related Health Problems (ICD-10-GM) diagnoses, patient age >18 and availability of high-quality, anonymised wound images.
In Essen, the images, except for MLU, were expert selected based on the ICD-10-GM codes19 and clinical data in electronic health record (EHRs) and then extracted manually. Images for MLU were manually selected as they were not represented in the ICD-10-GM system and were added when both venous congestion and reduced arterial blood flow were present. As the images were selected retrospectively from the image database, their age varied from 1 to 20 years.
In Erlangen, the images were extracted via the local Data Integration Centre—a service hub providing routine health data for research recorded in electronic systems.20 The health data contained the images and a core dataset such as the patient’s age and medical diagnosis. For our project, we used the images connected to diagnoses for VLU, ALU PG and DFU that were taken in the time period from 1 January 2021 to 30 March 2023.
In Melle, the images of the DFU patients were selected by clinical experts retrospectively from their records of patients with diabetes mellitus.
Table 1 provides an overview of the different types of wounds, the related ICD codes and their counts in relative and absolute numbers. The sample of images was determined by the availability of data from the Data Integration Centres in Erlangen and Essen and therefore can be regarded as a convenient sample.
Wound type, ICD-10 GM code, number of wound images across all three sites and their distribution
The dataset was split into a training and a validation split with a ratio of 85%–15% of the total data point. The model was trained on the data using ConvNeXt ‘B’,21 a CNN architecture inspired by visual transformers. The architecture was chosen as CNNs allow for relatively data-efficient training, and ConvNeXt is the currently best-performing architecture. We choose the ‘B’ variant of ContNext, since it was found to be sufficiently large to achieve high performance, with an average layer saturation of 38.9%22 when training the model from scratch on the dataset, indicating high parameter efficiency for the given task. One key challenge was the relatively small amount of data, making training from scratch impractical, since even small CNNs do not adequately learn discriminative features on the image, given the available data. To optimise performance on the small wound dataset, we choose a multistaged pretraining process, starting with a highly varied large-scale dataset followed by progressively smaller, more specific and higher quality datasets. The rationale behind this process was that initial stages would generate highly generalisable features that were improved by increasingly focusing on higher-quality data throughout the training stages. The weights were initially determined by first training the model as a Contrastive Language-Image Pre-training (CLIP) model23 on the LAION2B dataset.24 CLIP was necessary in this case, as LAION2B has no labels that could be used for classification. This first stage of pretraining was followed by fine-tuning on the ImageNet12K and ImageNet1K classification datasets.
To avoid unproductive layers,25 26 we increased the resolution to 256×256 input resolution while training and evaluating the model. The model was finally trained using mixed precision and a batch size of 16 with a cross-entropy loss. Otherwise, the hyperparameter configuration would have been equivalent to the A2 configuration of ‘ResNet strikes back’ by Wightman et al.27
Preprocessing and data augmentation strategies were also adapted without change from Wightman et al.27 The architecture itself remained unchanged from the original implementation21 except for the softmax output, which was reduced to the appropriate number of classes. Training was conducted for 300 epochs using mixed precision, checkpointing after each epoch. The final checkpoint was selected from this trajectory of checkpoints based on their balanced accuracy on the validation set.
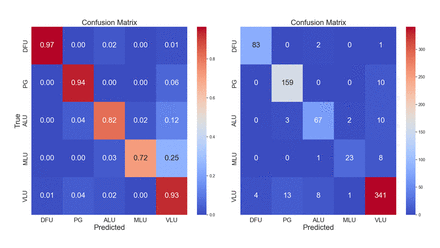
Since the dataset was highly imbalanced, we relied on multiple metrics and evaluation methods to quantify predictive performance. Our primary metrics were accuracy and balanced accuracy. The balanced accuracy weighs the samples based on their class, simulating balanced classes in the ground truth. To further breakdown the characteristics of the model, we further used the confusion matrix computed from the prediction on the validation set. The confusion matrices were computed with absolute values and normalised with respect to ground truth, to further characterise the predictive quality with respect to individual classes. To enhance the explainability of the validation samples, we additionally computed activation heatmaps with GradCam ++,28 highlighting the regions contributing to the predicted class. The latter was addressing the imbalance issue directly. However, in the case of overfitting, anomalous or unreasonable activation heatmaps (eg, the texture of the bed contributing more to the classification than the wound itself) could reveal overfitting scenarios.
A study flow diagram, visualising the process, can be found in the supplement (online supplemental figure 1).
[ad_2]
Source link



