
[ad_1]
Methodology
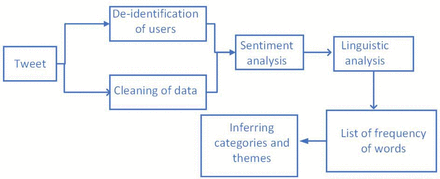
We analysed publicly accessible data from users posting about loneliness. Figure 1 illustrates our data analysis process using information collected from Twitter. As a social media platform, Twitter facilitates connectivity and opinion sharing, allowing users to post short messages up to 280 characters. Developers can access user data through Twitter’s publicly available API. We gathered relevant tweets about loneliness and stored them in a database. For data collection, we used keywords such as “lonely,” “loneliness,” “alone,” “isolated” and “isolation” for loneliness, as well as “awake,” “sleep,” “insomnia” and “night” for insomnia. We combined these terms, for example, ((“loneliness” AND “awake”) OR (“loneliness” AND “night”) OR (“loneliness” AND “sleep”) OR (“loneliness” AND “insomnia”)) and repeated this for other terms like “lonely,” “isolation” and “isolated.” The keywords for loneliness are taken from literature as studies which analyse loneliness through Twitter have used these keywords. For insomnia, as this is the first study on analysing insomnia through Twitter data, we composed the search keywords ourselves. The data collection spanned a week in October 2022, resulting in a total of 10 149 tweets.
Pipeline for analysis of Twitter data.
We used respective analyses of publicly available data of users posting about loneliness. Figure 1 presents our pipeline of analysis of data collected from Twitter. Twitter is a social media platform which is used for connectivity and opinion sharing and allows users to post via short messages consisting of 280 characters. Twitter gives access to the users’ data through its publicly available Twitter API for developers. The relevant tweets about loneliness were gathered and stored in a database. We created categories which are a combination of relevant words and phrases. These words and phrases convey meanings which can belong to the same broader division of sociopolitical or emotional-personal categories. After sentiment analysis, the tweets with negative sentiments were further analysed by counting the occurrence of each word. The highly occurring words were then reported if they were conveying a meaning.
We conducted sentiment analysis on the Twitter data using an NLP tool based on a psycholinguistic model to understand mental health issues. The collected tweets were stored in a database, and sentiment analysis was performed using the valence-aware dictionary for sentiment reasoning (VADER) tool from the natural language toolki.13 VADER is a lexicon and rule-based model for sentiment analysis. Before analysis, we cleaned the data by removing redundant characters, numbers, special characters, user profile IDs and information such as ‘retweet’.
If we were reporting all the tweets that contained feelings of loneliness, we would not have required a further step. In our case, the problem becomes determining the association between themes (which may represent loneliness) with the keywords depicting loneliness. For instance, we had to find what is the relationship between ‘hurt’, ‘sick’, ‘tired’, ‘sleep’, etc with the expression of loneliness. This task is usually carried out by the association of lexicon categories with tweets including the words ‘lonely’ or ‘alone’. To carry out this task, we use sentiment analysis. Sentiment analysis was carried out after cleaning the data such as removing redundant characters, numbers, special characters, users’ profile IDs and information such as ‘retweet’.
We stored the tweets with negative sentiments separately to carry out further analysis. We focused on negative sentiment tweets as the collected tweets also contain metaphorical use of lonely or loneliness which do not pertain to our use of loneliness. Such mention of loneliness is represented by the positive and neutral sentiment tweets. We did not carry out manual filtering of the tweets, hence inferring the consequences from tweets with non-negative sentiment would be not useful as the exact meaning of the mention cannot be found. Further, we carried manual analysis of the negative sentiment tweets to find out relevant topics and themes. Stop words were removed before this step. We found the number of occurrences of each word and phrase in the negative sentiment tweets. The manual analysis of the list of occurrences resulted in devising the larger socioeconomic or emotional-personal categories. These categories will provide insight into the relationship between various emotional-personal and sociopolitical themes and the expression of loneliness and insomnia on social media.
This method of searching for relevant categories of sociopolitical and personal-emotional content and topics was used because it has more flexibility. Usually, the n-gram method gives an association of words that co-occur and cannot be perceived to have happened by chance. However, that method would not give the occurrence of individual topics and words, thus the impact of a topic would not be known.
Sentiment analysis
VADER is specifically designed for analysing microblog content, such as Twitter posts. It combines lexicon-based (dictionary-based) analysis with a rule-based approach to assess sentiment. Unlike other lexicon-based sentiment analysers like Linguistic Inquiry and Word Count (LIWC), which only determine sentiment polarity, VADER also measures sentiment valence on a scale from 1 to 9.14 This sentiment score allows us to gauge the degree of positivity or negativity in a sentiment.
VADER’s valence assessment is based on rules that reflect the grammatical and syntactical conventions humans use to emphasise sentiment intensity. Another key feature of VADER is its ability to include sentiment-bearing lexical items such as emoticons, slang, acronyms and initialisms, which are common in social media contexts. The combination of valence polarity through both lexicon and rule-based approaches enables fine-grained sentiment analysis.
VADER addresses the limitations of lexicon-based analysers like LIWC by incorporating a machine-learning approach. Lexicon-based methods often face challenges in coverage, general sentiment intensity and the integration of new human lexical features. VADER overcomes these shortcomings, providing a more comprehensive sentiment analysis tool.
[ad_2]
Source link



