
[ad_1]
Discussion
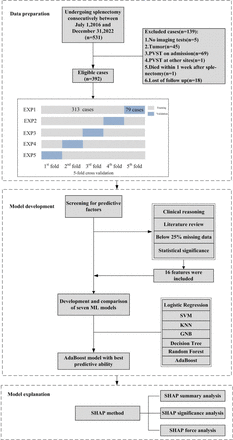
In this clinical study, we employed five distinct ML algorithms to predict the risk of PVST during the 3-month follow-up after splenectomy in patients with cirrhosis. Although some early predictive models have been developed using traditional statistical methods, the performance of ML approaches remained unclear. Our findings indicate that the ML-based prediction models can provide an initial risk assessment. Notably, the AdaBoost model demonstrates moderate discriminative ability in distinguishing between high-risk and low-risk patients, with an AUROC of 0.72 (95% CI 0.60 to 0.84). This highlights the potential of ML methods in clinical prediction.
We identified eight key clinical features as significant predictors of PVST risk, including ALB, PLT addition, DPV, GGT, LOS, APTT, D-dimer level and a history of preoperative gastrointestinal bleeding. While previous studies have explored PVST risk in patients with cirrhosis, few have used ML to construct predictive models.4 ML is particularly powerful for analysing complex, extensive data and can adeptly manage high variability and complicated intervariable relationships. Given the intricate nature of our clinical data, employing ML proved to be essential.
A key objective of the study was to develop an interpretable predictive model, and the trade-off between explainability and model performance was inevitable. By combining AdaBoost with SHAP, the study managed to strike a balance between interpretability and performance. While the AUROC of 0.72 indicates certain limitations, an AUROC range of 0.7–0.8 still holds clinical significance in some practical applications, particularly in scenarios where a balance between interpretability and performance is required. SHAP analysis provided valuable insights into the importance of each feature in the model, offering explanations for the predictions and enhancing their clinical relevance.
The SHAP scores indicated noteworthy insight into the importance of each feature in the AdaBoost model. PVST pathogenesis is multifactorial, primarily driven by Virchow’s triad—hypercoagulability, endothelial injury, and hemodynamic stasis—which collectively contribute to thrombus formation in the portal venous system. multifactorial, influenced by Virchow’s triad—hypercoagulability, endothelial injury and reduced blood flow.19 25 We found the DPV to be a significant predictor. A wider portal vein may decrease blood flow velocity, create turbulent flow conditions that damage the venous endothelium and facilitate thrombus formation, supporting findings from prior studies. Additionally, our results highlighted elevated D-dimer levels as a risk factor for postoperative thrombosis. Previous studies26 have established a correlation between increased D-dimer levels and heightened coagulation activity, indicating a propensity for thrombosis. Our findings align with these established links, confirming the role of D-dimer in predicting postoperative outcomes. Notably, we found a correlation between a history of preoperative gastrointestinal bleeding and postoperative thrombotic outcomes, supporting existing literature.19 This underscores the importance of comprehensive preoperative assessments in identifying at-risk patients. Furthermore, additional indicators of PVST risk included factors such as length of hospital stay, ALB levels, APTT and variations in PLT counts. These eight clinical parameters together form a robust foundation for constructing predictive models aimed at anticipating PVST occurrence in patients with cirrhosis following splenectomy.
In summary, our study highlights the utility of ML in predicting PVST risk in a complex clinical landscape and identifies critical clinical features that contribute to the prediction. The findings suggest that integrating these parameters into clinical practice can enhance risk stratification and potentially guide personalised patient management after splenectomy.
Our model was designed with both model developers and clinicians in mind. Through interpretability tools such as SHAP values and feature importance, developers can gain a better understanding of the model’s internal mechanisms, allowing for optimisation of its performance. Additionally, explainability is equally crucial for clinicians. Clinicians need to comprehend the model’s predictions and the rationale behind them to trust and adopt its recommendations. We achieve this by providing clear interpretability results, which help clinicians understand the model’s prediction process, thereby enhancing their trust in the model. We employed SHAP values as the primary method for explainability. SHAP values quantify the contribution of each feature to the model’s predictions, enabling clinicians to identify which features have the greatest influence on the results. We presented feature contribution plots that illustrate the positive and negative impacts of each feature on the prediction results, along with concise textual explanations to help clinicians intuitively grasp the model’s reasoning. Explainability holds significant value in clinical practice. For example, by identifying high-impact features (such as ALB/DPV), clinicians can conduct more accurate risk stratification and develop personalised treatment plans. For high-risk patients, doctors can implement more proactive monitoring and intervention strategies, which may improve patient outcomes. Explainability helps clinicians build trust in the model. If doctors can understand why the model makes a particular prediction, they are more likely to integrate it into their clinical practice. For instance, through SHAP value plots, doctors can visually see the contribution of a specific feature to the prediction, thereby bolstering their confidence in the model. Despite using explainability tools like SHAP values, interpreting complex models remains challenging. For example, deep learning models may require more advanced explanation strategies to uncover their internal logic.
Several limitations should be considered. First, potential biases, such as selection bias, information bias and missing data biases, may impact the reliability of the findings. Second, the reliance on a study population from a single-centre clinical study could limit the generalisability of the results. While the data from a single centre may not fully capture the diversity of broader clinical settings or patient populations, this limitation does not diminish the value of the model developed and validated in this study. The model demonstrates practical utility for patients within the study centre and lays a solid foundation for future multicentre research. Third, the models lack external validation. However, employing iterated cross-validation enhances result reliability and reduces the risk of overfitting, preventing an excessively optimistic evaluation of model performance. Fourth, additional data, like imaging data and novel biomarkers, have the potential to improve prediction accuracy. Future research should investigate the integration of these variables to strengthen the AdaBoost models proposed in this study.
Future research should focus on advancing the application of ML in predicting PVST. This includes emphasising comprehensive data collection, such as imaging data, to enhance prediction accuracy and strengthen the AdaBoost models developed here. Further optimisation of model selection and tuning is necessary, with consideration given to dataset characteristics (eg, non-linear relationships, high-dimensional features and class imbalance) when selecting models. Ensemble models are generally robust choices, but linear models can also perform well through appropriate tuning and selection of kernel functions. During the tuning process, it is recommended to employ a broader parameter search and cross-validation to ensure the model can adapt to the dataset’s characteristics. Adopting a multicentre study design will enhance the external validity of the research results. Multicentre studies will enable us to better evaluate the applicability of these results across different clinical environments and patient populations. Furthermore, researchers should consider developing prediction models for both immediate and long-term time frames, distinguishing between early and long-term predictors to better address variations in PVST occurrences.
[ad_2]
Source link



