
[ad_1]
Discussions
This study evaluated the in-hospital coding of 17 Charlson comorbidities in DAD from four hospital sites against chart-reviewed databases spanning 20 years. We found that DAD increasingly undercoded conditions but remained relatively stable for certain conditions (eg, diabetes, metastatic cancer and peripheral vascular disease). The longitudinal variations in the coding quality of comorbidities exerted minimal impact on in-hospital mortality predictions.
The quality of administrative data is crucial to inform the health services policy, programme planning and public health stakeholders in downstream processes. In the Canadian context, CIHI and the Public Health Agency of Canada, among other agencies, emphasise the importance of maintaining accuracy, timeliness and usability in data quality assessments in their frameworks for continuously evaluating administrative health databases against these quality dimensions.18 19 Aynslie Hinds et al2 reviewed the validation studies of administrative data and found that the common investigation subjects included case definitions for chronic conditions and diagnostic codes of comorbidity indices. While many studies, such as those by Smith et al7 and Iwig et al,8 propose new tools for assessing data quality, there is limited evidence of their widespread implementation or evaluation of long-term results. A few studies have examined quality consistency over time.7 Our study extended the literature by analysing the consistency of coding practices over time within the same healthcare system, offering a focused examination of changes in coding accuracy for multiple comorbidities.
Compared with the work of Wei et al,20 which reviewed existing validation studies on 81 conditions completed before 2014, our findings revealed a similar trend in conditions like diabetes coding accuracy, which remained relatively stable across years. For some other conditions, they reported hypertension sensitivity at 65%, while our 2015 cohort had a lower sensitivity of 53%; for congestive heart failure, the sensitivity ranged from 20% to 94%, while our results showed a decline from 69% in 2003 to 53% in 2022. These findings roughly align with our validation results. However, these results were obtained from different studies and diverse healthcare systems. By conducting the analysis within the same healthcare system over time, we could offer insights into the temporal changes in administrative data coding practices, providing a clearer picture of how comorbidity coding accuracy evolves and highlighting areas in need of improvement.
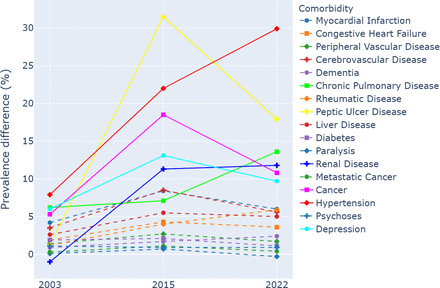
The prevalence difference analysis highlights the increasing under-reporting of several comorbidities, such as dementia, chronic pulmonary disease and hypertension, over the years, and further highlights the present reality where the hospital system has experienced increased in-patient volumes and coders are required to meet this turnover. The work by Tang et al11 further demonstrated that there is a gap between clinician documentation and the administrative coding process. This trend points to the need for improved communication between the stakeholders on the coding practices or the adoption of tools to support the coding process. Additionally, the consistent prevalence of certain conditions like diabetes and metastatic cancer in both chart data and ICD-10 coding underlines the reliability of these conditions in administrative data for epidemiological tracking.
The trends in coding performance over time provide valuable insights into the accuracy of capturing comorbidities. Overall, specificity remained high across all years for most conditions, indicating a consistent ability to correctly identify non-cases. However, sensitivity showed a noticeable decline for several conditions, such as myocardial infarction, congestive heart failure and peripheral vascular disease, which suggests that the ability to detect true cases has weakened. For their detection, including automation tools for analysing existing data sources, such as electronic health records, could be beneficial. Regarding PPV, a decline was observed in certain conditions like peptic ulcer disease and paralysis, indicating a loss of accuracy in identifying true positives. Conversely, renal disease showed a substantial increase in PPV, from 63.7% in 2003 to 96.3% in 2022, which may reflect improved recognition for this condition. NPV remained relatively stable across most conditions. These findings highlight the need for ongoing evaluation of coding practices to ensure accurate identification of comorbidities in administrative data.
The large prevalence differences in conditions like chronic pulmonary disease and hypertension, with increasing under-reporting over time, directly affect performance metrics such as sensitivity, PPV and NPV. The decreased prevalence in ICD-10 coding for these conditions leads to reduced sensitivity and PPV, as many true cases are missed. Consistent under-reporting can also affect NPV, overestimating the non-case population by misclassifying some true cases. In contrast, conditions with low prevalence differences, like peripheral vascular disease, diabetes and metastatic cancer, have more stable metrics, as consistent coding accuracy better reflects the true disease burden.
The observed decline in the C-statistics for predicting in-hospital mortality over the years when using ICD-10 coding, relative to chart data, can be attributed to the differences in the prevalence and coding accuracy of comorbidities. Conditions such as chronic pulmonary disease and hypertension, which showed increasing under-reporting in ICD-10, led to a greater misclassification of true positive cases. They are critical comorbidities that significantly affect in-hospital mortality risk, resulting in a drop in C-statistics (from 0.84 in 2003 to 0.78 in 2022). On the other hand, conditions with more consistent coding practices, such as diabetes, contributed to relatively stable PPVs and a smaller impact on the overall predictive model.
Several factors contribute to the discrepancies in coding performance. Out of 17 conditions, diabetes and conditions that contributed most to prolonged stays in care facilities were mandated to be coded in the Canadian administrative database. Diabetes must be coded whenever it is documented, as outlined in the CIHI coding guidelines.21 This requirement stems from the serious nature of diabetes and its potential for long-term complications affecting multiple systems in the body. Other conditions are only coded when they meet specific clinical criteria. This explains the relatively stable coding quality of diabetes and some other conditions. A few qualitative studies have indicated high barriers to achieving high-quality coding in the Canadian context,10 11 including incomplete documentation from providers, the requirement for faster turnaround time resulting in high pressure on coding specialists and discrepancies in used terminologies between coding specialists and providers. The advent of the digital age has led to increased adoption of electronic health records in acute care facilities in recent years, compared with the early days in 2003. This increased adoption has likely resulted in a higher volume of data associated with coding. For example, the province of Alberta is near completion of implementing a province-wide clinical information system (ie, Connect Care) incorporating EHR in all acute-care facilities throughout the province. Therefore, the above qualitative factors and changes in health system capacity could explain the decrease seen in this study.
The impact of including prior years’ data was notable. The prevalence of comorbidities increased with the inclusion of earlier years’ data, with hypertension showing the most significant increase. For this reason, many cohort selection algorithms typically use claim codes or hospitalisation codes over 2 years to define chronic conditions.22 Sensitivity and NPV were improved by including more data, whereas specificity and PPV slightly declined. The C-statistics for in-hospital mortality predictions decreased somewhat over the years but remained reasonably high (around 80%). This indicates the reliability of administrative data in providing accurate information for predicting patient outcomes, showcasing the robustness of healthcare analytics. After including data from prior years, the C-statistic remained stable, indicating that conditions in earlier episodes of care were not severe enough to impact in-hospital mortality during the latest hospitalisation.
Our study has several limitations. First, our cohorts are restricted to four acute care facilities in Alberta. Hence, the results are not externally validated and require further verification. Second, the three datasets were collected at different time points and may be influenced by differing health systems and clinical practices. Last, this study is limited to inpatient data only, and as such, it may not be fully representative of outpatient coding practices. However, the study contains several strengths. First, the coding quality results are based on three separate chart review databases conducted on the same facilities spanning a long period of time. Second, the results are based on real-world evidence of system practices and can be helpful to inform the stakeholders.
Alberta Health Services’ Data and Analytics department is currently implementing an infrastructure that can potentially implement large language models (LLMs) into its arsenal of tools. Perhaps there exists a future where LLMs can assist the coders with information extraction on comorbidities from the large volume of EHR data. Nevertheless, additional non-technical factors (eg, documentation quality) require multidisciplinary conversations and collaboration between all stakeholders (eg, health system, physicians, coding specialists) to improve the coding quality of comorbidities. For instance, the quality of the DAD is closely tied to the quality of EHR data, as ICD coders can only use what physicians document in patient charts. Any gaps or inaccuracies in EHR data directly affect the quality of ICD coding. Many physicians may not realise the link between their documentation and ICD-based systems, highlighting the need for collaboration to enhance data accuracy. All of these will be explored in the future.
[ad_2]
Source link



